
Tesseract-OCR样本训练

之前闲着写了一个识别小篆的APP,用到了Tesseract-OCR,由于没有小篆的训练数据,只能自己搞,五六千个字吧,一个个调整,当时花了挺多时间的,哈,记录下训练过程
Tesseract-OCR 仓库地址 :https://github.com/tesseract-ocr/tesseract
1. 下载安装Tesseract
到这里下载,下载完成自行安装
这时候已经可以使用自带的训练数据进行文本识别了,具体命令为
1 | tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...] |
简单点就 tesseract myscan.png out就可以了
好了,今天主要讲怎么训练,关于使用可以查看文档
2. 下载box editor
box editor在训练过程中需要用到,提前下载。下载页面,我下载的是java版本,也就是jTessBoxEditor,具体下载地址是这里,使用时需要有java环境,因为我写Android,环境都是配好的,反正配置起来也不难,搜一下就行,略过。下载回来解压,双击jar能正常打开,基本就没问题了
3. 准备训练内容
要识别什么文字,就准备什么文字。这里我们识别小篆,于是我准备了一份含有6598个已经去除重复汉字的文档,通过设置字体将所有文字转换为方正小篆体,随后调整每行文字个数为10个,文字大小为28号,行间距为1.0倍,方便识别。然后通过系统的打印功能,将整个文档打印成tif格式的图片,部分截图

全部转换为图片后,按照chi.xiaozuan.exp0, chi.xiaozuan.exp1, ……的规律依次命名各个图片。
4. 创建box文件
命名完成后,执行
1 | tesseract chi.xiaozuan.exp0 chi.xiaozuan.exp0 -l chi_sim batch.nochop makebox |
命令生成box文件,并且按照相同的命令将剩余的其他图片也生成box文件,命令执行成功后,文件夹内会出现与图片名字相同的box文件。
如果样本多的话,建议写个批处理循环跑。
5. box校正
生成box文件后,一般情况下生成的box并不是全部正确的,因此需要手工调整,使其正确切分文字,此时打开前面下载的jTessBoxEditor,选Box Editor,打开图片挨个调整,校正每个文字,校正完成后如下图: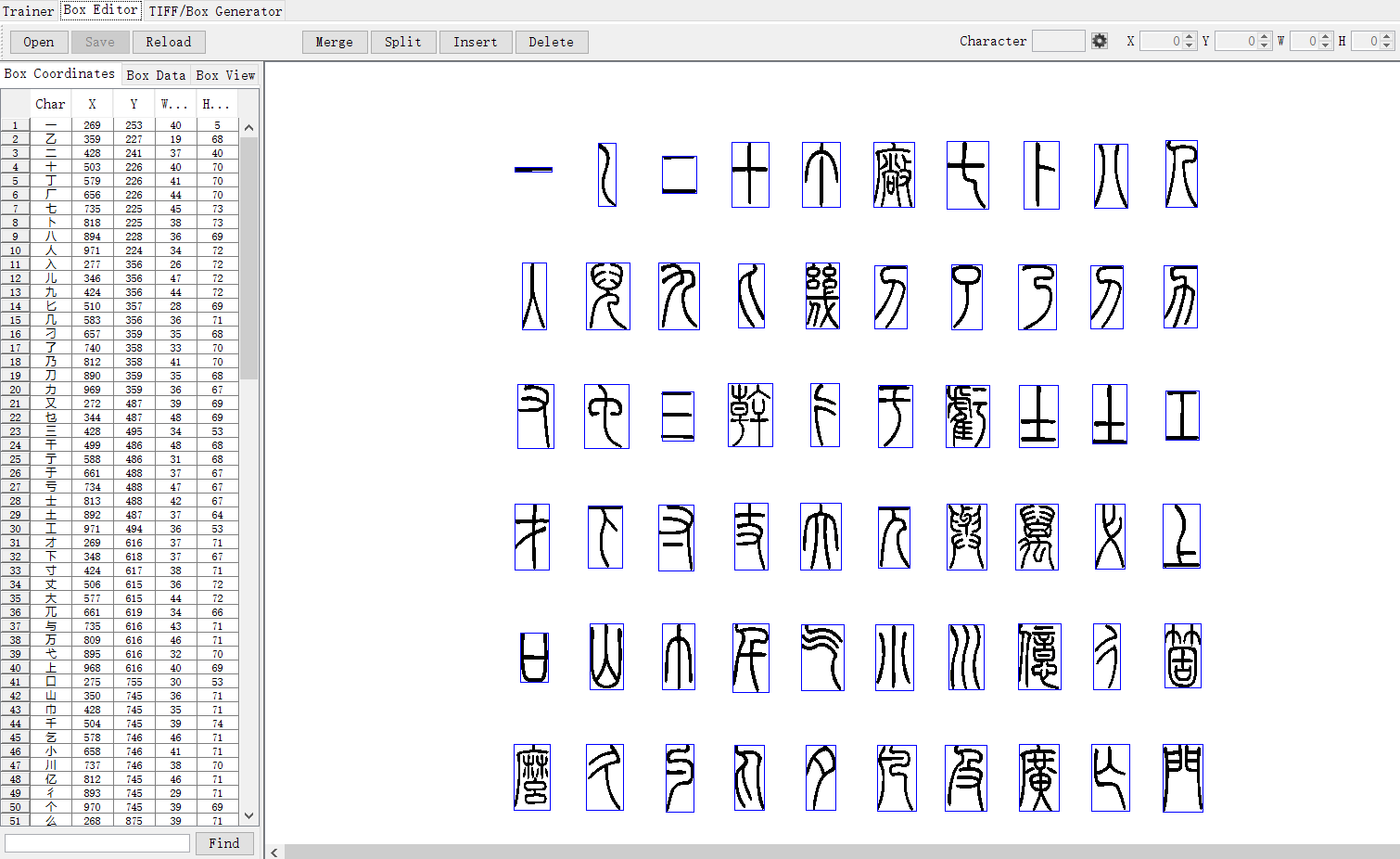
校正需要使每个小篆文字刚好被方框框住,并且在左侧对应的表格内填入正确的简体字。merge,split,insert,delete分别为合并,分割,插入和删除,另外选择Box View可以使用一些快捷键,具体看图:
(大部分时间都花在了这个步骤,基本每个字都要调整,搞吐血了都快)
6. 训练
使用修改正确的box文件对Tesseract进行训练,执行以下命令:
1 | tesseract.exe chi.xiaozuan.exp0.tif chi.xiaozuan.exp0 nobatch box.train |
训练完成后,系统将会生成同名的tr文件
同样,如果样本多,建议跑循环
7. 生成Character集合
训练完成后需要生成Character集合,执行以下命令:
1 | unicharset_extractor.exe chi.xiaozuan.exp0 chi.xiaozuan.exp1 chi.xiaozuan.exp2…… |
需要将所有图片合并成一个Character集合,生成一个名为unicharset的文件
8. 创建字体特征文件
在训练目录下创建一个名为font_properties的字体特征文件,且该文件需要不含BOM头,文件内容为xiaozuan 0 0 0 0 0
9. 创建剩余所需文件
执行以下两条命令:
1 | mftraining.exe -F font_properties -U unicharset -O chi.xiaozuan.exp0.tr chi.xiaozuan.exp1.tr…… |
1 | cntraining.exe chi.xiaozuan.exp0.tr chi.xiaozuan.exp1.tr…… |
执行完成后会生成inttemp、pffmtable、normproto、shapetable四个文件,以及一个叫chi.unicharset的文件,手动修改前四个文件的名称为chi.nttemp、chi.pffmtable、chi.normproto、chi.shapetable
10. 合并文件
最后合并以上文件生成训练好的可以直接使用的数据文件,执行以下命令:
1 | combine_tessdata chi |
命令执行完成后会生成chi.traineddata,这就是我们最终需要的数据,可以直接丢在Tesseract的数据文件夹中使用。
11. 附上我的批处理脚本,路径次数自行修改,也可以使用相对路径
11.1. makebox
1 | echo run make box |
11.2. train
1 | echo run train |
11.3. unicharset
1 | echo run unicharset_extractor |
11.4. mftraining
1 | echo run mftraining |
11.5. cntraining
1 | echo run cntraining |
 wechat
wechat alipay
alipay





